DS4Sci_EvoformerAttention: Code and Tutorial
Model partner: OpenFold team, Columbia University

Introduction
OpenFold is a community reproduction of DeepMind’s AlphaFold2 that makes it possible to train or finetune AlphaFold2 on new datasets. Researchers have used it to retrain AlphaFold2 from scratch to produce new sets of model parameters, studied the early training phase of AlphaFold2 (Figure 1), and developed new protein folding systems.

While OpenFold does apply performance and memory optimizations using state-of-the-art system technologies, training AlphaFold2 from scratch is still computationally expensive. The model at the current stage is small in absolute terms, with just 93 million parameters, but it contains several custom attention variants that manifest unusually large activations. During the “finetuning” phase of a standard AlphaFold2 training run, the logit tensor produced in just one of these variants–one designed to attend over the deep protein MSAs fed to the model as input–is in excess of 12GB in half precision alone, dwarfing the peak memory requirements of comparably sized language models. Even with techniques like activation checkpointing and DeepSpeed ZeRO optimizations, this memory explosion problem heavily constrains the sequence lengths and MSA depths on which the model can be trained. Furthermore, approximation strategies can significantly affect the model accuracy and convergence, while still resulting in memory explosion, shown as the left bar (orange) in Figure 2.
To address this common system challenge in structural biology research (e.g., protein structure prediction and equilibrium distribution prediction), DeepSpeed4Science is addressing this memory inefficiency problem by designing customized exact attention kernels for the attention variants (i.e., EvoformerAttention), which widely appear in this category of science models. Specifically, a set of highly memory-efficient DS4Sci_EvoformerAttention kernels enabled by sophisticated fusion/tiling strategies and on-the-fly memory reduction methods, are created for the broader community as high-quality machine learning primitives. Incorporated into OpenFold, they provide a substantial speedup during training and dramatically reduce the model’s peak memory requirement for training and inference. This allows OpenFold to be experimented with bigger and more complex models, and longer sequences, and trained on a wider spectrum of hardware.
Methodology
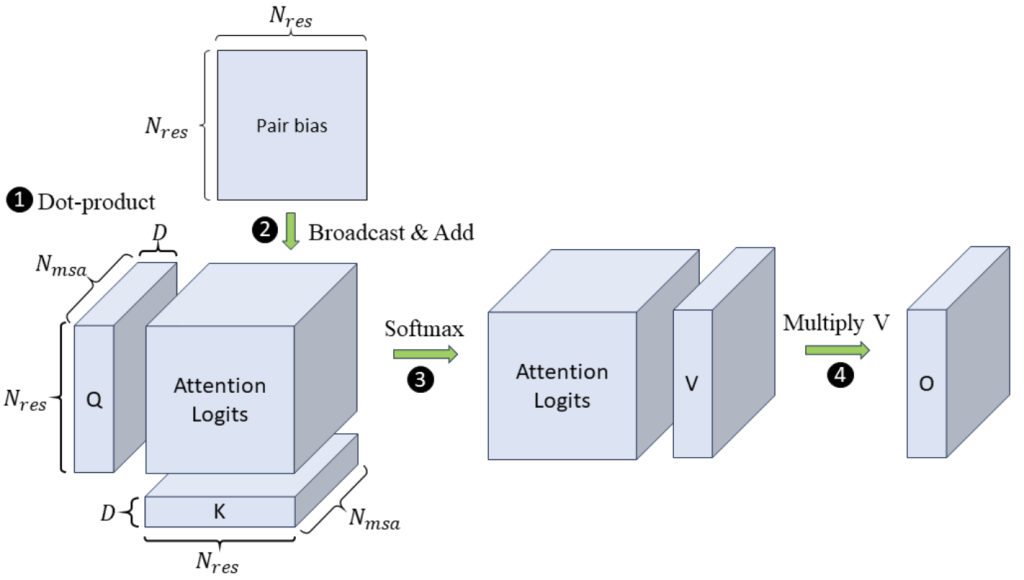
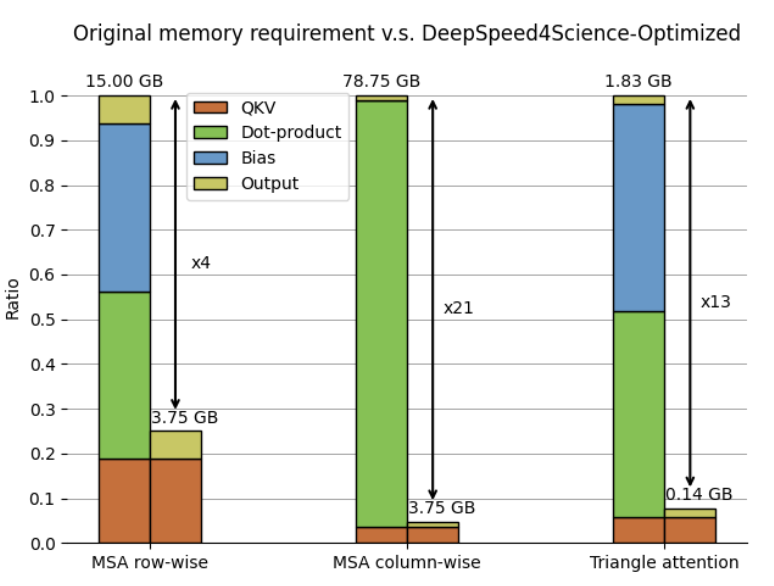
Problem Definition. The Evoformer-centric models such as OpenFold and others typically use four attention variants to process the 4D sequence tensors: MSA row-wise, MSA column-wise, and two kinds of Triangular. In particular, the input tensor is of shape 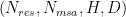




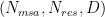



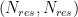
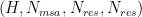
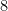
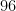
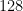
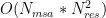
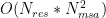
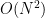
Existing techniques for long sequences cannot effectively address such memory explosion challenges in Evoformer’s specialized attention for structural biology. For example, MSA row-wise attention and two Triangular attention apply a bias term to the attention logits, and the bias term’s gradients are required during backward. As shown in step 2, the pair bias is derived by projecting the pair-wise representation and is used to adjust the attention logits based on the structure of residues to satisfy the spatial constraints. Take FlashAttention as an example; it cannot integrate these backward-compatible bias terms directly. Furthermore, the bias requires appropriate broadcasting to match the shape of attention logits before adding. It thus also needs to be mirrored in backward computing. Recognizing these challenges, DeepSpeed4Science addresses this memory inefficiency problem by designing customized, exact attention kernels for these attention variants in EvoformerAttention and boosting the training/inference efficiency.
Our customized highly memory-efficient DS4Sci_EvoformerAttention kernels fuses the four steps computation and calculates the attention logits in tiles. Specifically, in the forward kernel, each thread block computes a tile of 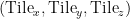
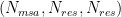
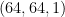
The bias-adding needs to be effectively broadcasted to match the bias shape with the attention logits. For example, in MSA row-wise attention, the residue pair-wise representation in shape 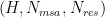
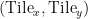
In backward, the gradient of the bias terms equals the gradient of attention logits. However, we need to reverse the broadcast operation. That is, the gradients along the broadcast dimension need to be accumulated. Specifically, the shape of attention logits gradients is 

How to use DS4Sci_EvoformerAttention
To use DS4Sci_EvoformerAttention in user’s own models, we need to import DS4Sci_EvoformerAttention from deepspeed.ops.deepspeed4science:
from deepspeed.ops.deepspeed4science import DS4Sci_EvoformerAttention
Take MSA row-wise attention as an example. The input tensors Q, K, V are in shape [Batch, N_msa, N_res, Head, Dim]. The pair bias is [Batch, 1, Head, N_res, N_res] and a mask to handle the padding in the batch of residue sequences with different lengths, [Batch, N_seq, 1, 1, N_res]. Simply call the kernel as
out = DS4Sci_EvoformerAttention(Q, K, V, [res_mask, pair_bias])
Detailed instructions on how to use DS4Sci_EvoformerAttention can be found at DeepSpeed4Science tutorials.
Case Study: OpenFold
Check out how OpenFold uses DS4Sci_EvoformerAttention to unblock their scientific discoveries.